
PRS Challenge News:
• Human-centered In-building Embodied Delivery Benchmark
Code
Paper
• CVPR 2024 Embodied AI Workshop PRS Challenge Award Winners
• We move the online evaluation to the Eval AI .
• CVPR 2024 Embodied AI Workshop PRS Challenge Award Winners
• We move the online evaluation to the Eval AI .

Task —— Human-centered In-building Embodied Delivery:
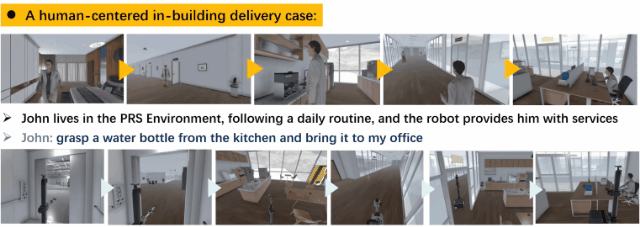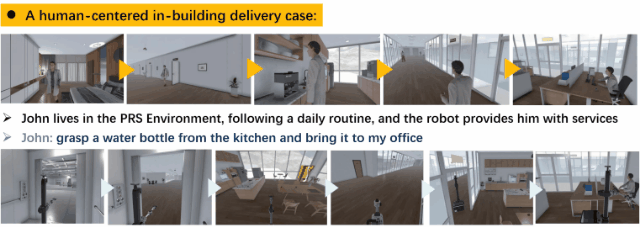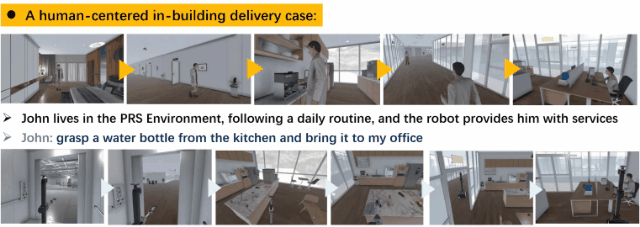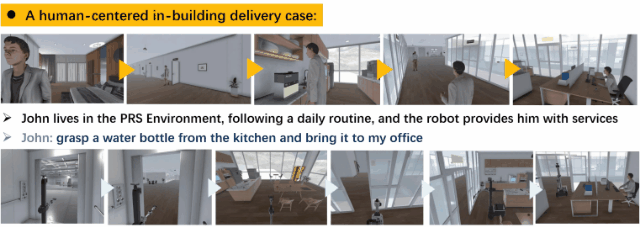
We have developed a brand-new virtual environment system from scratch, constructing a multi-level connected building space modeled after a polar research station. This environment also includes autonomous human characters and robots with grasping and mobility capabilities, as well as a large number of interactive items. Based on this environment, we have built a delivery dataset containing 13k language instructions to guide robots in providing services. We simulate human behavior through human characters and sample their various needs in daily life. Finally, we proposed a method centered around a large multimodal model to serve as the baseline system for this dataset. Compared to past embodied data work, our work focuses on a virtual environment centered around human-robot interaction for commercial scenarios. We believe that this will bring new perspectives and exploration angles to the embodied community.
- Purpose: Deliver the requested item to the vicinity of the designated character.
- Delivery Items: Items in the environment that can be grabbed and moved.
- Customers: Ten virtual human characters with different daily activities inside the building. They will move within the building for their own purposes.
- Spatial Scope: The reachable areas within different rooms of a three-story building.
- Time Setting: Real-world time, but simulation can be accelerated.
- Scenario Map: 2D projected obstacle map of scenario, and pre-sampled panoramic photos at various locations on the map.
- Robot Positioning: We adopt relative localization rules for robot positioning.
- Robot Actions: Movement, Joint control, and manipulation.
- Robot Skills: Local navigation by coordinate, 6-DOF visual grasping, and pose adjustment.
- Sensors: Two RGB-D cameras (head and arm), tactile sensors.
- Success Criteria: Place the target object within a 3 meter range of the target person.
- Constraints: Completion within 8 minutes without any dangerous collisions and unavailability of environmental metadata.
- Evaluation: Based on the total time taken and success rate of the object delivery, grasping the target object, and identifying the target character.

Dataset
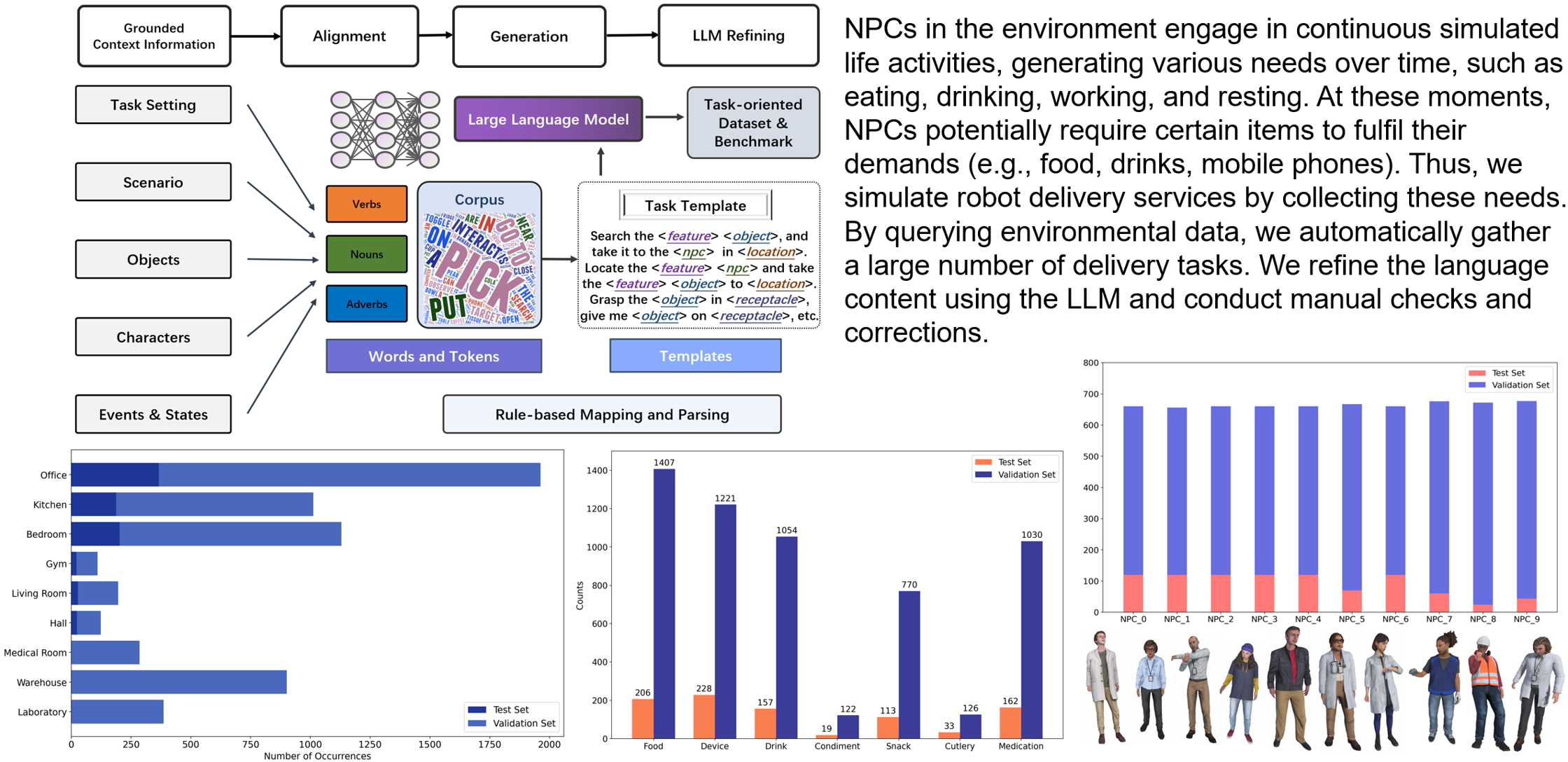
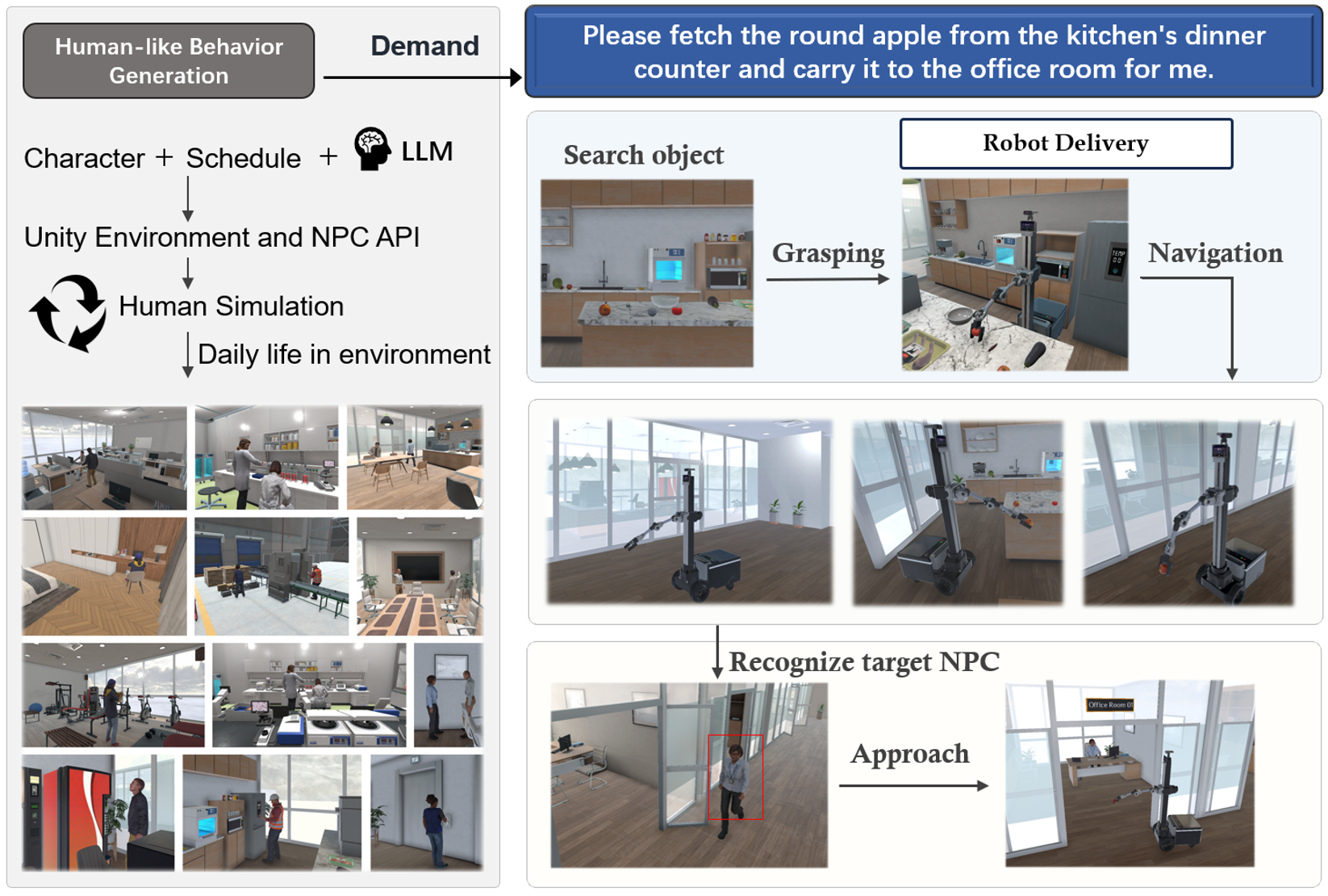
A data generation instance. We generate human activities, target objects, robot positions, task instructions, and a complete process of robot execution based on the settings combined with large models.
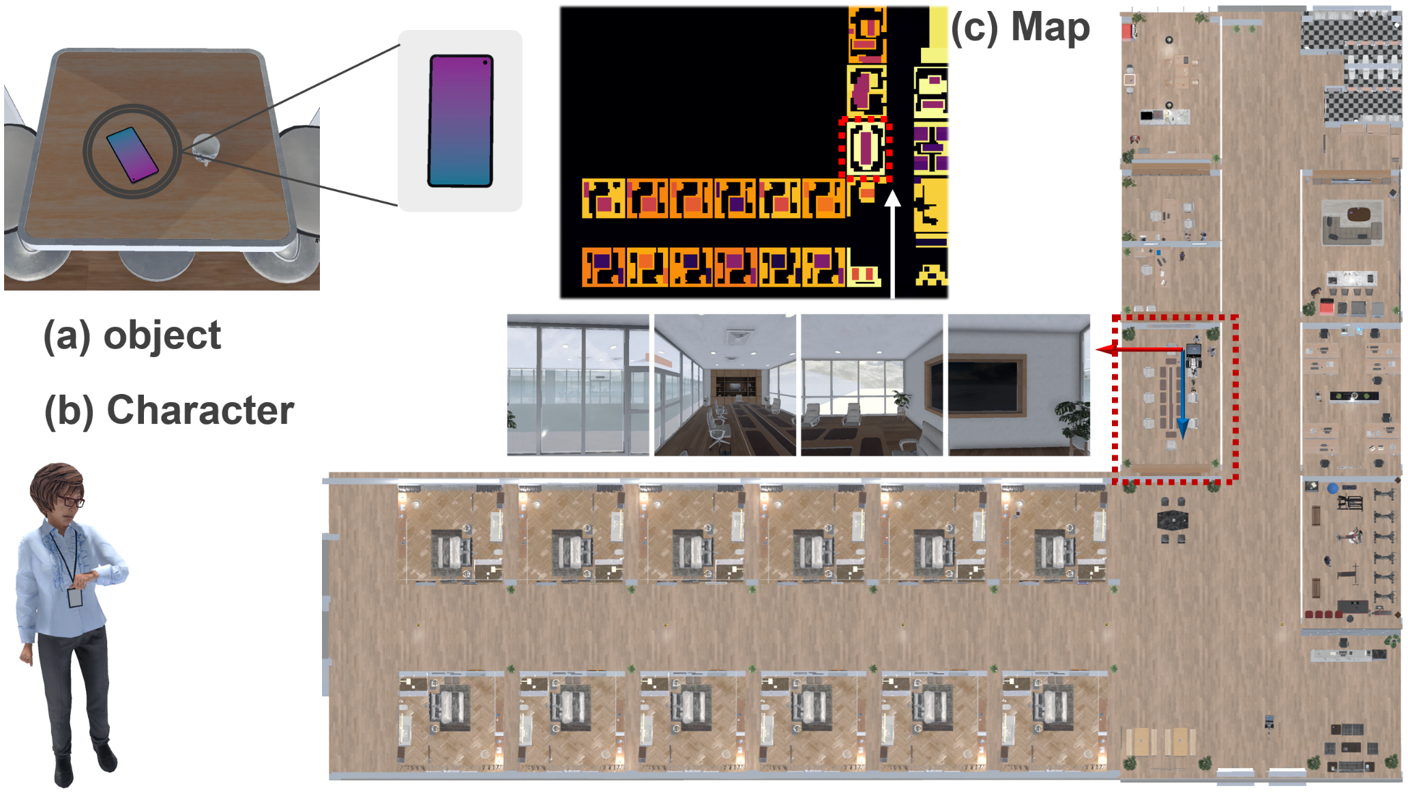
The available information in task.
Task Definition and Settings
- Robots operate within a relatively fixed building space.
- The residents within the building are the recipients of the service, and they typically move throughout the building based on personal needs and objectives. Robots can access relevant information about the recipients to better locate and identify them.
- The transportation service may cover a substantial area, involving different floors and rooms.
- Robots typically need to understand human instructions in order to search for and retrieve the correct target items, and deliver them to the designated recipients.
→ Based on the aforementioned scenario requirements, we provide the following task definition and settings, as shown in the following table:
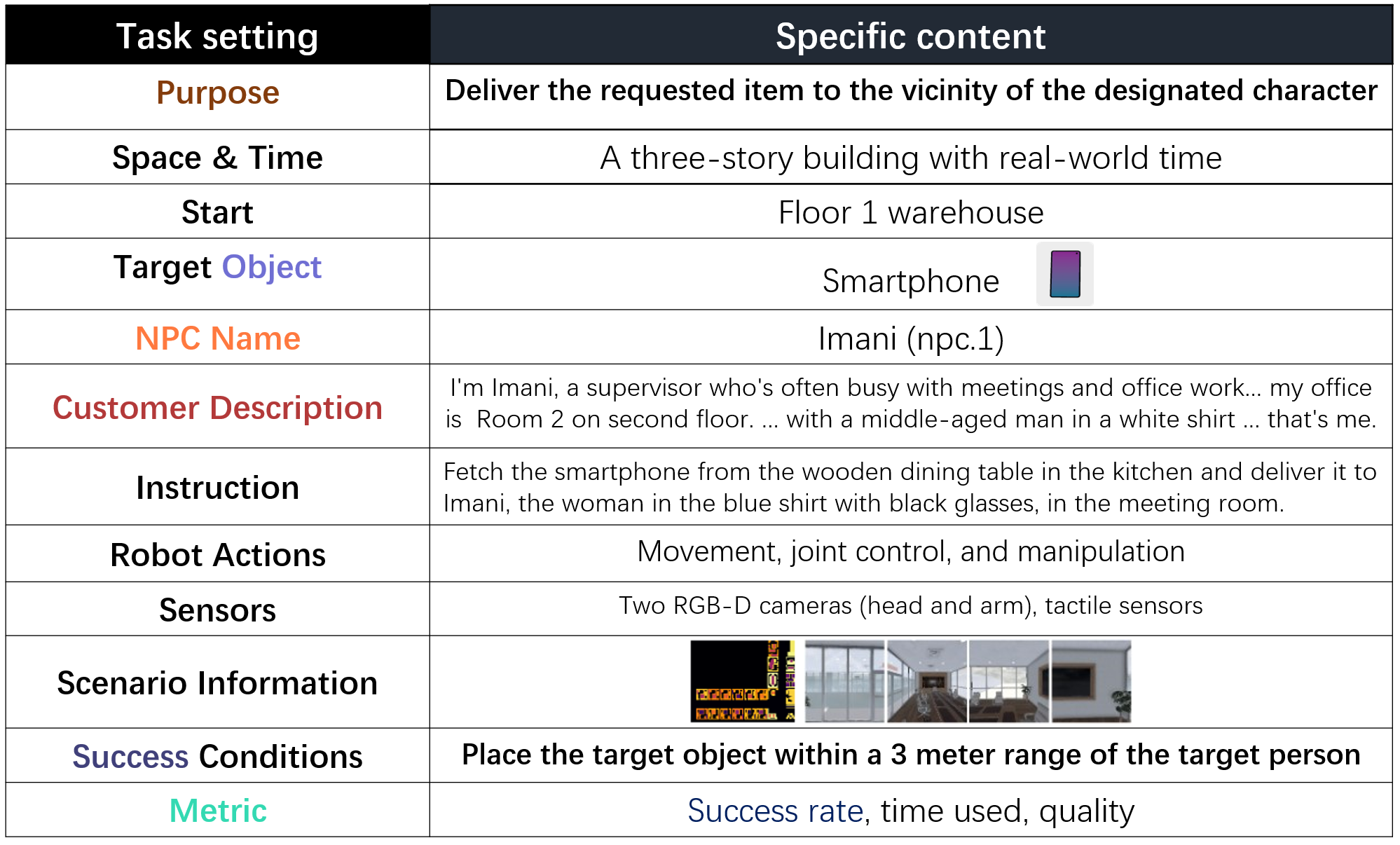
Human-centered in-building embodied delivery task setting.
Baseline
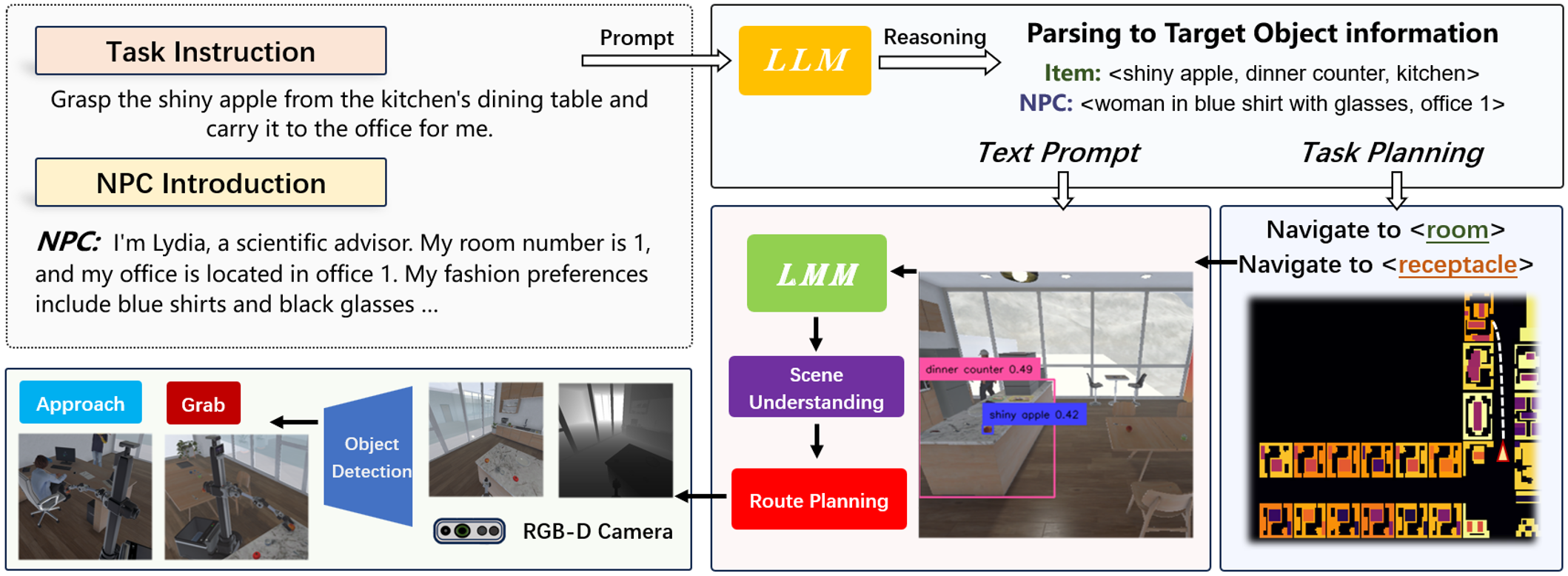
Modular method for the robot delivery task with LLM and LMM.
Simulation Environment

We present a multi-story polar research station building. Virtual environments typically need to meet the task requirements. Clearly, to depict corresponding commercial scenarios, existing environments are still constrained by factors such as the richness of the scene, the complexity of space, character portrayal, continuous environmental state systems, long-term operation, and the setup of items and robots. Consequently, we have crafted a brand-new virtual environment, the PRS Environment, which is specifically tailored to facilitate the various generalist agent and robotic tasks.